In het programma ‘Digitaal Erfgoed voor het Onderwijs’ werkten Kennisnet en het Netwerk Digitaal Erfgoed (NDE) samen om erfgoed, met behulp van ict, structureel een plek in het onderwijs te geven. Een van de vragen in het programma was: hoe kunnen musea, archieven en andere culturele instellingen hun onderwijsaanbod beter vindbaar maken?
Om een aanzet te geven tot een antwoord op deze vraag, deden Kennisnet en NDE een onderzoekproject, waarbij termen uit verschillende bronnen werden verzameld. In dit artikel beschrijven we het Linked Data model dat we gebruikten om deze termen te modelleren.
Aanpak
Kennisnet maakt veelvuldig gebruik van Linked Data, en het gebruik van Linked Data is ook voorgeschreven in de DERA (Digitaal Erfgoed Referentie Architectuur). Het doel van dit project was om een methodiek te ontwikkelen om de infrastructuren van onderwijs en erfgoed beter op elkaar aan te sluiten. De termen modelleren als Linked Data was dan ook een logisch uitgangspunt.
Bij het ontwerp van het model hielden we rekening met relevante bronnen, waaronder de doelen in de API van de SLO Curriculum Browser, het Termennetwerk van Netwerk Digitaal Erfgoed en Wikidata.
We maakten het model in RDF, het meestgebruikte framework voor Linked Data. Voor ons eigen model waren we vrij in het maken van ontwerpkeuzes, maar omdat we gegevens van anderen willen hergebruiken en willen koppelen met bestaande modellen maken we gebruik van bestaande Linked Data ontologieën.
Het uitgangspunt: belangrijke metadata van termen
Eerst stelden we vast welke metadata we per term wilden vastleggen. Zo kwam het vaak voor dat we een oorspronkelijke term aanpasten, om deze aan te laten sluiten bij de voorkeursspelling. We wilde deze informatie echter niet verloren laten gaan, en de bron zelf ook vastleggen. Ook wilden we het vakleergebied of leerniveau bij een term opnemen, als dit in de bron expliciet was aangegeven. In totaal stelden we zo’n 30 belangrijke metadatavelden vast (zie de bijlage onderaan).
Modelleren van metadatavelden tot Linked Data
Na het vaststellen van de metadatavelden volgde de uitdaging deze als Linked Data te modelleren. Hierbij wilden we niet een eigen model ontwikkelen, maar gebruik maken van bestaande standaarden. De use case voor het gebruik van de termen was leidend voor de keuze van deze standaarden.
SKOS
We wilden in eerste instantie vooral onderwijstermen vastleggen. De nadruk lag hierbij op toepassing en herbruikbaarheid door culturele instellingen. Hierbij is het wenselijk dat culturele instellingen zelf een koppeling kunnen maken tussen de onderwijstermen en hun eigen terminologiebronnen, om te zien welke verbanden ze kunnen leggen tussen hun collecties en het onderwijs. Omdat veel culturele instellingen terminologiebronnen gebruiken die gebaseerd zijn op SKOS, hebben we deze standaard veel gebruikt.
Provenance ontologie en de DublinCore ontologie
We hebben termen automatisch geëxtraheerd en handmatig geselecteerd uit diverse bronnen. We wilden hierbij de informatie over de oorspronkelijke bron behouden. Daarnaast wilden we de methode van selecteren en extraheren vastleggen. Zo gebruikten we de extractietool TextRazor om termen te halen uit de onderwijsdoelen in de SLO Curriculum Browser. Hierbij wilden we de URI van het doel waar een term uit komt behouden. Daarbij gaf TextRazor per geëxtraheerde term een Wikidata-URI, die we ook vast wilden leggen. Voor het vastleggen van dergelijke herkomstinformatie gebruikten we de standaarden van de PROV ontology en DublinCore.
We wilden leerniveau en vakleergebied zo goed mogelijk modelleren. Dit bleek lastiger dan verwacht. Er is een internationale standaard voor het modelleren van leermiddelen: LRMI. Deze bouwt voort op Schema.org en wordt onderhouden en doorontwikkeld binnen de DublinCore gemeenschap. LRMI leek dus perfect voor onze use case.
We konden LRMI echter niet gebruiken, omdat onze dataset geen leermiddelen bevat, maar enkel metadata die aan leermiddelen kan worden gekoppeld. Uiteindelijk kozen we voor het modelleren van leerniveau en vakleergebied ook voor DublinCore (respectievelijk dcterms:educationLevel en dcterms:subject). Daarbij drukt SLO zelf in Linked Data uit of iets een vakleergebied of niveau is.
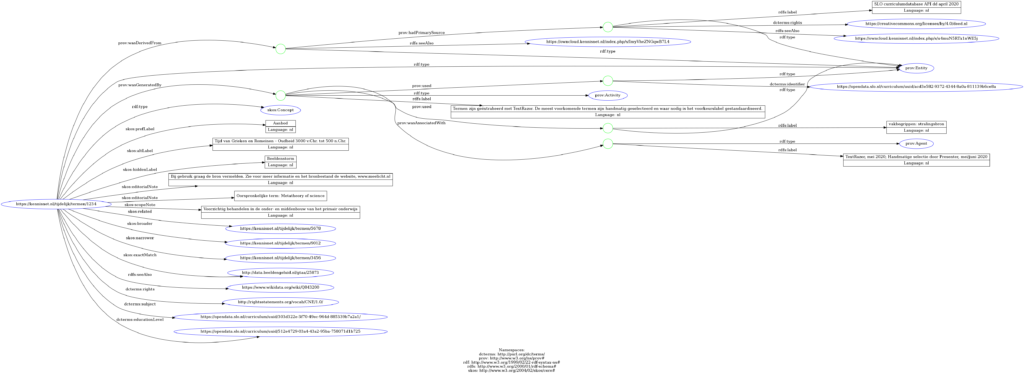
Fictief voorbeeld van de modellering van een term in het Linked Data model. Download het bronbestand om in te zoomen op de details.
{kind=link}
Redactioneel gemak: van Airtable naar Linked Data
In totaal selecteerden we bijna 5.500 termen. Deze zetten we in het online relationele databasesysteem Airtable, omdat dit systeem de flexibiliteit en toegankelijkheid bood die we nodig hadden voor het beheer van de termen tijdens het project. Het is echter niet mogelijk om data in Airtable te modelleren als Linked Data. Daarom ontwikkelden we een script om de data te exporteren en in ons model te gieten.
Mogelijke vervolgstappen
Het termenproject was onderdeel van het programma ‘Digitaal Erfgoed voor het Onderwijs’, dat eind juni 2021 ten einde kwam. Het doel was om te komen tot een methodiek van het vormen van een termenlijst, en aanbevelingen te doen voor de inzet hiervan.
De inzichten uit het project leverden een bijdrage aan de doorontwikkeling van de visie op onderwijskundige metadata binnen Kennisnet binnen de leermiddelenketen in het onderwijs. Daarbij hebben meerdere culturele instellingen aangegeven interesse te hebben in de termenlijst, om een beter beeld te krijgen van hoe hun aanbod en terminologie aansluit op het onderwijs. Kennisnet streeft ernaar om, met deze kennis, samen met partners in het onderwijsveld te komen tot een betere termenlijst voor meerdere vakgebieden, om deze bijvoorbeeld te kunnen gebruiken voor het metadateren van leermiddelen.
Bijlage
| Metadatavelden | Toelichting | Model |
| File | Het oorspronkelijke bestand waar de term in is overgenomen vanuit de bron (niet publiek). | prov:wasDerivedFrom (en onderliggende modellering) |
| Voorkeurslabel | De voorkeurspelling van het label van een concept. | skos:prefLabel |
| Bron | De bron waar de term uitkomt, gekoppeld aan een URL en rechtenstatus. | prov:hadPrimarySource (en onderliggende modellering) |
| Oorspronkelijke term | De oorspronkelijke spelling van een term. Dit kunnen ook meerdere woorden zijn, zoals een zoekopdracht of zin (bv: een kerndoel). | skos:editorialNote |
| Vakleergebied | Het vakleergebied waar de term bij hoort. Meerdere waardes mogelijk. Alleen ingevuld als deze informatie beschikbaar was. | dc:subject |
| Niveau | Het leerniveau waar de term bij hoort. Meerdere waardes mogelijk. Alleen ingevuld als deze informatie beschikbaar was. | dc:educationLevel |
| Concepttype | Het type concept waar de term toe behoort, zoals een persoonsnaam of geografische naam. Niet altijd ingevuld. | rdf:type => skos:Concept
[Toekomst: schema.org klasse] |
| Alternatief Label | Alternatieve spelling van het Voorkeurslabel, bijvoorbeeld een andere spelling van een persoonsnaam. (‘Rembrandt van Rijn’ is het Voorkeurslabel van het Alternatief label ‘Rembrandt’) | skos:altLabel |
| Verborgen Label | Verborgen spelling van het Voorkeurslabel. Veelgemaakte spelfouten of alternatieve, ongewenste schrijfwijzen. | skos:hiddenLabel |
| Gerelateerde term | Term die is gerelateerd aan het Voorkeurslabel. Bijv.: ‘tekenen’ en ‘schilderen’ zijn aparte termen, maar zijn beide creatieve handelingen en hebben daarom met elkaar te maken. | skos:related |
| broaderTerm | De bovenliggende term van het Voorkeurslabel. Bijv.: de bovenliggende term van ‘afvalscheiding’ is ‘afval’. We hebben deze zonder aanpassingen overgenomen uit de bron en niet zelf aangepast of ingevuld. | skos:broader |
| narrowerTerm | De onderliggende term van het Voorkeurslabel. Bijv.: de onderliggende term van ‘afval’ is ‘afvalscheiding’. We hebben deze zonder aanpassingen overgenomen uit de bron en niet zelf aangepast of ingevuld. | skos:narrower |
| Redactionele opmerking | Opmerking over het redactionele proces of andere aandachtspunten, bijvoorbeeld voorwaarden voor hergebruik. | skos:editorialNote |
| typicalAgeRange | Hierin wordt aangegeven of een term (on)geschikt is voor een specifieke leeftijdsgroep. | skos:scopeNote |
| Rechten: term | De rechten van een term. Deze zijn nog onbepaald. | dcterms:rights |
| Rechten: bron | De rechten van de bron waar een term uitkomt. | dcterms:rights |
| Geëxtraheerd uit – URI | Bij de SLO termen staan de oorspronkelijke links (URIs) naar de leerdoelen waar ze uit zijn geëxtraheerd. | prov:Entity |
| Geëxtraheerd uit – label | De tekst waar een term automatisch of handmatig uit is geëxtraheerd. | prov:Entity |
| Activity (methode) | De totstandkoming van de (selectie van) de term. Bijv: Automatisch uit de SLO doelen geëxtraheerd met TextRazor; Handmatig geselecteerd. | prov:wasGeneratedBy (en onderliggende modellering) |
| Agent (hulpmiddel voor methode) | Het hulpmiddel dat gebruikt is. Bijv: TextRazor; Handmatige selectie | prov:wasGeneratedBy (en onderliggende modellering) |
| Zie ook | Link naar een gerelateerde bron, in dit geval Wikidata. Deze Wikidatakoppeling is gemaakt door de tool TextRazor. Deze tool is gebruikt om termen uit de SLO doelen te extraheren. | rdfs:seeAlso |
NB: In het visuele model staan nog meer velden. Dit betreft de modellering van een experiment waarbij we automatische koppelingen hebben gelegd tussen de onderwijstermen en termen in thesauri uit het erfgoedveld. Dit experiment is niet verder uitwerkt en aangescherpt. Om die reden delen we deze onderliggende data en de bijbehorende modellering nog niet. Enkel de match met een andere thesaurus wordt nu uitgedrukt in het model. Vanuit de URI die hoort bij zo’n exactMatch kunnen de broader, narrower en related terms worden benaderd, evenals bijvoorbeeld het altLabel, hiddenLabel en de scopeNote.
Licentie: Creative Commons Naamsvermelding 4.0 CC BY 4.0
![]()